
티스토리 뷰
실습 데이터 모음
- 실습 파일 쿠팡 한개 카테고리의 모든 상품 정보 1020개
-
result.json
다운로드
- 쿠팡 키워드 noodle로 검색한 결과
-
noodles.json
다운로드
- naver에서 강남역 맛집으로 검색한 결과
-
gangnam.json
다운로드
- 타이타닉 생존자 데이터
파일 읽어오고 저장하기
루트 디렉토리 바꾸기
jupyter notebook에서 실행하는 경우 root를 현재 파일이 있는 위치로 바꾸기 위함
import os
os.chdir(os.getcwd())csv읽어오기
df = pd.read_csv("/com/array/data.csv")json 읽어오기
import pandas as pd
df = pd.read_json("./naverKeywordResult.json")
print(df.count())df만들기
print("av:", df['price'].mean())
print("std:", df['price'].std())
print("var:", df['price'].var())
d = {'col1': df['price'].mean(), 'col2':[]}
dfResult = pd.DataFrame(data=d)import pandas as pd
web_stats = {'day':[1,2,3,4,5,6,7],
'visitors':[43, 44, 45, 46, 47, 48, 58],
'bounce_rate':[89, 67, 90, 73, 28, 89, 41]
}
df = pd.DataFrame(web_stats)
print(df)json형식 df로 만들기
import pandas as pd
owner = {'p1.age': [56], 'p1.sex':[1], 'p2.age':[53], 'p2.sex':[2]}
pop = {'p1.age': [56], 'p1.sex':[1], 'p2.age':[53], 'p2.sex':[2], 'p3.age':[4], 'p3.sex':[1]}
df_owner = pd.DataFrame(owner)
df_pop = pd.DataFrame(pop)
print(df_owner)
print(df_pop)dic형식을 df로 만들기
컬럼명 확인하기
df.columns결과
Index(['id', 'reviewServiceType', 'reviewType', 'reviewContentClassType',
'reviewContent', 'createDate', 'reviewDisplayStatusType', 'repurchase',
'reviewScore', 'reviewRankingScore', 'writerMemberId',
'writerMemberIdNo', 'writerMemberNo', 'writerMemberProfileImageUrl',
'checkoutMerchantNo', 'checkoutMerchantId', 'channelId',
'channelServiceType', 'orderNo', 'productOrderNo', 'productNo',
'productName', 'productOptionContent', 'largeCategorizeCategoryId',
'middleCategorizeCategoryId', 'smallCategorizeCategoryId',
'detailCategorizeCategoryId', 'productUrl', 'originProductNo',
'eventTitle', 'reviewEvaluationValueSeqs', 'writerMemberMaskedId',
'profileImageSourceType', 'reviewAttaches', 'repThumbnailAttach',
'repThumbnailTagNameDescription', 'merchantNo', 'merchantName',
'isMyReview', 'reviewTopics', 'parentReviewSeq', 'helpCount',
'modifyDate', 'reviewCommentIds', 'reviewComments',
'reviewInspectionPolicyReason', 'bestReview', 'bestReviewSelectDate'],
dtype='object')
json으로 저장 할 때 index없이 저장하기
import pandas as pd
df = pd.read_csv('./turn_farm_2.csv', encoding='utf-8')
df.reset_index().to_json('./turn_farm_2.json', orient='records')excel로 저장 하기
import pandas as pd
def save(df, filename):
writer = pd.ExcelWriter(filename)
df.to_excel(writer, 'Sheet1')
writer.save()https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_excel.html
Pandas Configuration
출력 할 때 생략 안되게 하기
pd.set_option('display.max_colwidth', -1)
1.0 pd.set_option('display.max_colwidth', None)모든 Column보이기
pd.set_option('max_columns', None)Type관련
string -> date time으로 필드 바꾸기
df['updated_at'] = pd.to_datetime(df['updated_at'], format="%Y/%m/%d")
df['createDate'] = pd.to_datetime(df['createDate'])
int형인 phone_number0, phone_number2 를 str형태로 바꾸기
df = pd.read_json("./user_info.json",
dtype={'phone_number0':'str', 'phone_number2':'str'})010 3588 등 핸드폰번호를 이렇게 따로 컬럼으로 나누어서 저장 한 경우 pandas 디폴트로 불러오면 010은 10 등으로 짤리고 0358은 앞에 0이 짤린 358로 불러와진다. str을 int로 convert하기 때문이다. 그래서 type을 지정 해주면 str로 받아오기 때문에 전화번호 등이 짤리지 않는다.
df = pd.read_json('mafra_total_data.json', dtype={'data_id':'str'})20191014000000001320 이런 식으로 자리수가 긴 숫자의 경우 숫자형으로 불러오면 뒤에 숫자가 잘리는 경우가 있습니다. 그래서 dtype을 str로 받아오는 방법으로 처리합니다.
column에 index부여하기
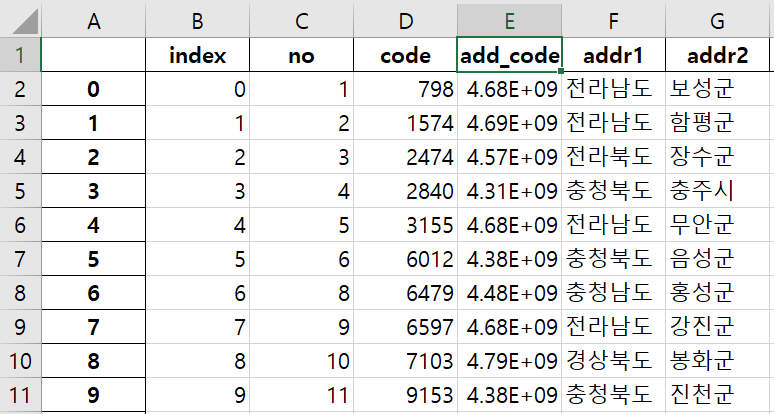
df.to_excel(), df.to_json()을 하면 index가 자동으로 부여되는데 때로는 특정 column을 index로 지정해 주어야 할 필요가 있습니다. 그때 .set_index()를 사용합니다.
import pandas as pd
df_acc = pd.read_excel('2017시설접근성_add_code.xlsx', sheet_name='pivot')
df_acc = df_acc.set_index('add_code')필터링
조건으로 필터링 하기
df1103 = df[(df['updated_at'] >= '2018-11-03') & (df['updated_at'] < '2018-11-04')]특정 키워드가 포함되어 있는 레코드 필터링
competitors = ["매일", "서울", "남양", "파스퇴르", "연세"]
for competitor in competitors:
result = df[df['name'].str.contains(competitor)]
print(result.count())top5 블로거가 쓴 글 개수
for item in df.head(5)['bloggername']:
resultDf = df[df['bloggername'] == item]
print(item, len(resultDf))필터링 하고 결과 for each로 출력 하기 .iterrows()
import pandas as pd
df = pd.read_json("../week5/results.json")
df['postdate'] = pd.to_datetime(df['postdate'], format="%Y%m%d")
df2 = df[df['postdate'] >= '2019-01-01']
print(df2.count())
print(type(df2.head(5)))
for item in df2.head(5).iterrows():
print(item)
int형인 phone_number0, phone_number2 를 str형태로 바꾸기
df = pd.read_json("./user_info.json",
dtype={'phone_number0':'str', 'phone_number2':'str'})year month date뽑기
df['year'] = df['createDate'].dt.strftime('%Y')
df['month'] = df['createDate'].dt.strftime('%m')
df['date'] = df['createDate'].dt.strftime('%d')
yy-mm-dd로 바꾸기
df['createDate'] = pd.to_datetime(df['createDate']).dt.strftime('%Y-%m-%d')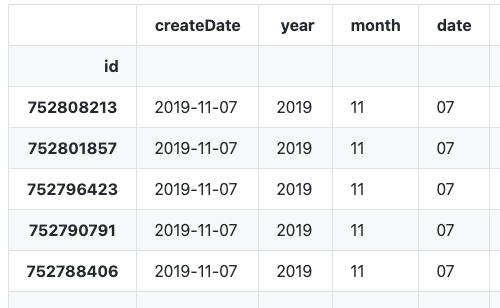
하지만 createDate의 type은 Object가 됩니다.
날짜로 변경한 후 필터링 하기
import pandas as pd
df = pd.read_csv("./tsv.csv")
df['created_at'] = pd.to_datetime(df['created_at'])
dfDay1 = df[(df['created_at'] > '2018-11-22') & (df['created_at'] < '2018-11-23')]
print(dfDay1['created_at'].astype)결과
11 2018-11-22 12:25:55.415
12 2018-11-22 12:42:03.450
13 2018-11-22 15:37:42.989
14 2018-11-22 23:19:07.470
Name: created_at, dtype: datetime64[ns]>created_at필드를 날짜로 변경한 후 2018-11-22일 보다 크고 2018-11-23보다 작은 데이터 추출
%Y%m%d형식을 datetime으로 변경
20200101, 20210331 이런 모양이 %Y%m%d 형식 입니다. format을 지정하지 않고 그냥 변환 하면 변환이 잘 안됩니다.
df['delngDe'] = pd.to_datetime(df['delngDe'], format='%Y%m%d')
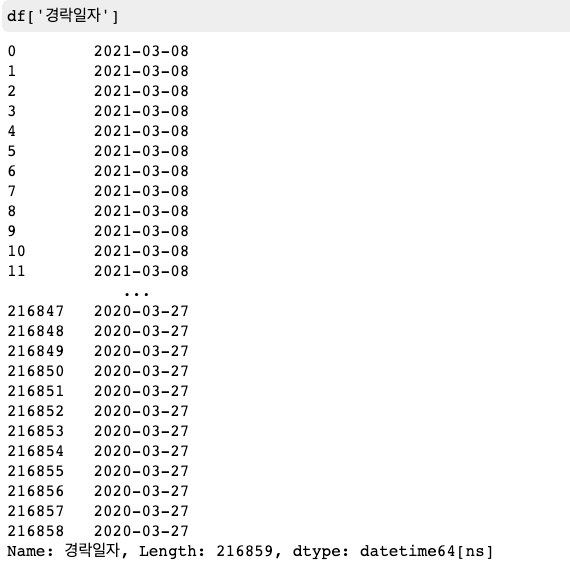
datetime64로 잘 바뀌었습니다.
created_at, user_id 두가지 컬럼 출력하기
print(dfDay1[['created_at', 'user_id']])결과
created_at user_id 0 2018-11-22 09:08:01.781 id1 1 2018-11-22 09:24:37.782 id2 2 2018-11-22 09:24:49.625 id3
정렬하기
df2 = df[['postdate', 'title', 'bloggername', 'link']]
df2Sorted = df2.sort_values(['postdate'], ascending=[0])
print(df2Sorted)
필드가 0 한개만 있을 때 내림차순
df = df.sort_values(by=[0], ascending=True)- user_id, amount, direction필드 추출해서 direction이 HELLO, WORLD인 것 각각 분리하기
dfc = df[['user_id', 'amount', 'direction']]
print(dfc)
df_hello = dfc[(df['direction'] == 'HELLO')]
df_world = dfc[(df['direction'] == 'WORLD')]created_at, user_id 두가지 컬럼 출력하기
print(dfDay1[['created_at', 'user_id']])결과
created_at user_id
0 2018-11-22 09:08:01.781 id1
1 2018-11-22 09:24:37.782 id2
2 2018-11-22 09:24:49.625 id3정렬하기
df2 = df[['postdate', 'title', 'bloggername', 'link']]
df2Sorted = df2.sort_values(['postdate'], ascending=[0])
print(df2Sorted)필드가 0 한개만 있을 때 내림차순
df = df.sort_values(by=[0], ascending=True)
user_id, amount, direction필드 추출해서 direction이 HELLO, WORLD인 것 각각 분리하기
dfc = df[['user_id', 'amount', 'direction']]
print(dfc)
df_hello = dfc[(df['direction'] == 'HELLO')]
df_world = dfc[(df['direction'] == 'WORLD')]특정 필드만 copy하기
dfBuy = df[['updated_at','buy_user_id', 'amount']].copy()hello라는 이름의 컬럼 추가하기
df['hello'] = ""
df.columns
Index(['abstract', 'authors', 'institutions', 'journal', 'keywords', 'title'], dtype='object')
df.columns
Index(['abstract', 'authors', 'institutions', 'journal', 'keywords', 'title','hello'],journal에서 숫자로된 4글자 매칭된 것 중 맨 앞에 선택 하기
pattern = re.compile("[0-9]{4}")
df['year'] = df.apply( lambda row: pattern.findall(row['journal'])[0], axis=1)필드 이름 바꾸기
dfBuy= dfBuy.rename(columns={"buy_user_id": "user_id"})
price에서 ,빼기(thousand separator)
df = pd.read_json("./products.json")
df['price'] = df['price'].str.replace(',', '').astype(float)
print(df['price'])숫자 형식 3자리마다 컴마 소수점 2째자리로 나오게 하기
ex) 9,706,137.47
print(dfGroup['amount'].map('{:,.2f}'.format))csv로 저장하기
'amount', 'buy_user_id', 'updated_at' 3개의 필드만 뽑아서 updated_at <= '2018-11-06' 인 데이터를 뽑아서 저장하기
dfTarget = df[[_'amount', 'buy_user_id', 'updated_at'_]].copy()
dfTarget = dfTarget[dfTarget.updated_at <= "2018-11-06"]
dfTarget.to_csv('target.csv', index=False)group by하기
dfGroup = dfTarget.groupby('buy_user_id').sum()날짜로 group by하기
'경락일자' 컬럼이 datetime이어야 합니다.

set_index('경락일자')를 하면 위와 같이 나옵니다.
df = df.set_index('경락일자')
gr = df.groupby(pd.Grouper(freq='M'))
그룹으로 묶어서 sum하기
dfBuy.groupby(['user_id']).sum()group by
gr = df2.groupby('name')
gr_alex = gr.get_group('Alex')
print(gr.mean())
print(gr.describe())
gr.plot.bar()
plt.show()group by한 후에 특정 column에 해당하는 결과만 뽑기
gr_by_gender = df.groupby(by='ADQ2')
print(gr_by_gender['competency'].describe())컬럼 뽑아서 계산하기
axis = 1가 핵심 이걸 써야 row연산이 됨
df['middle_score'] = df[['score1', 'score2', 'score3', 'score4', 'score5']].apply(lambda series:sum(sorted(series.tolist())[1:4])/3 , axis=1)타이타닉 선실별 생존자 합계(group by)
import re
import pandas as pd
def get_class(room_code):
match = re.match(r"([A-Z]+)([0-9]+)", room_code, re.I)
if match:
items = match.groups()
return items[0]
else:
return room_code
data_df = pd.read_json('./passengers.json')
data_df['Class'] = data_df.apply(lambda row: get_class(row['Cabin'].split(' ')[0]), axis=1)
gr = data_df.groupby('Class')
print(gr.sum())
날짜 between
# df = df.set_index('경락일자')
위와 같이 날짜가 index인 경우에 가능합니다.
df2020 = df.loc['2020-01-01':'2020-03-31']
df2021 = df.loc['2021-01-01':'2021-03-31']2020년 1월 1일 ~ 2020년 3월 31일, 2021년 1월 1일 ~ 2021년 3월 31일 데이터만 뽑기
iloc이용하기
iloc는 위치를 기반으로 슬라이싱 합니다. loc는 레이블 기준으로 슬라이싱 합니다.
0:10열을 선택 합니다.
df.iloc[:, 0:10]결과
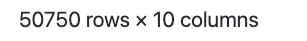
31:80 column에 nan이 있으면 0으로 채우고 int로 바꿈
df.iloc[:, 31:80] = df.iloc[:, 31:81].fillna(0).astype(int)concat(합치기)
targets = [df1, df2]
pd.concat(targets)Join(.merge()) 하기
[
Python Pandas Merge(Join) 조인 합치기
krksap.tistory.com/1468 내용이 길어져서 위 글에서 분리 했다. 'Python Pandas 사용 방법' www.youtube.com/watch?v=xNkLIimJlKA 이 내용은 데이터베이스 정규화, Join에 대해 알고 써야 해서 위 링크를 첨부한..
krksap.tistory.com
](https://krksap.tistory.com/1740)
Group by하기
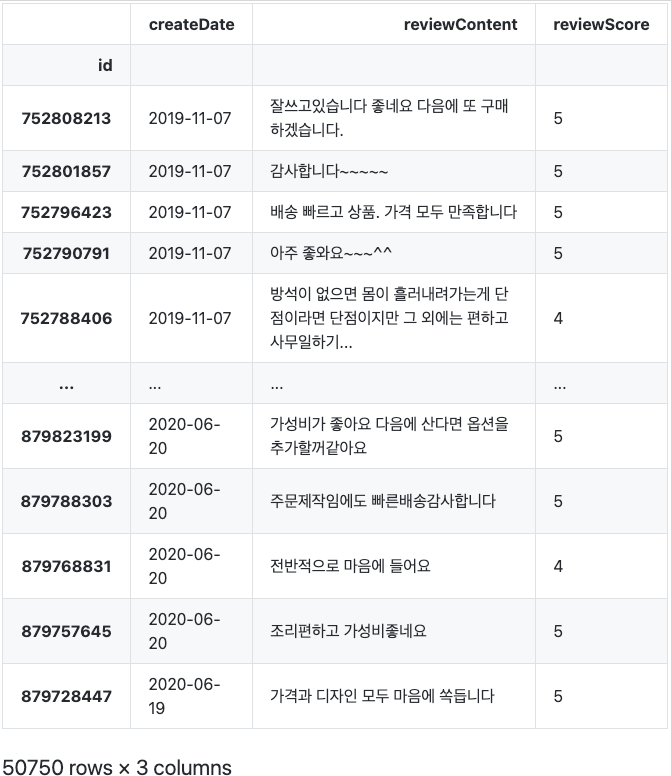
위 데이터는 2015년부터 2020년 6월까지 올라온 5만개 리뷰 데이터 입니다. 위 데이터는 모든 데이터라서 집계된 값을 보고 싶다면 처리를 해주어야 합니다.
우리가 하고 싶은 작업은 6년 동안 하루에 리뷰가 몇개가 올라왔는지를 집계하는 것입니다. 그럴때 쓰기 좋은 것이 group by입니다.
groupby()를 쓰면 그룹으로 묶을 수 있습니다. 그런데 groupby()만 하면 데이터로 보이진 않습니다.
gr = df.groupby('createDate')
그래서 groupby는 한 후에 .count(), .mean(), .sum()등을 해주어야 합니다.
gr = df.groupby('createDate').count().count()를 쓰면 날짜별로 데이터가 몇개인지를 세어줍니다.
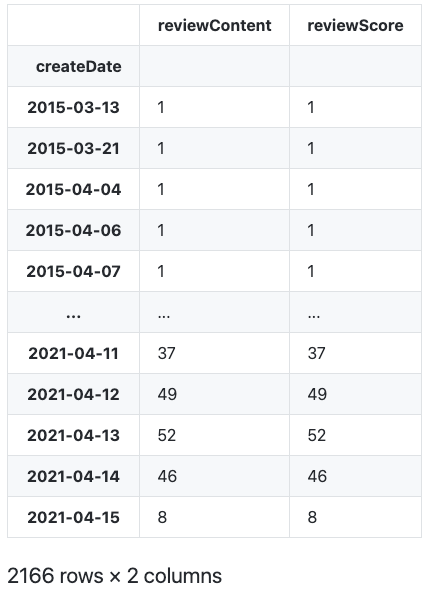
2166개 row라서 한눈에 안보이기 때문에 그래프를 그려보겠습니다.
gr = df.groupby('createDate').count()
fig, ax = plt.subplots(figsize=(15,7))
gr['reviewContent'].plot(ax=ax)
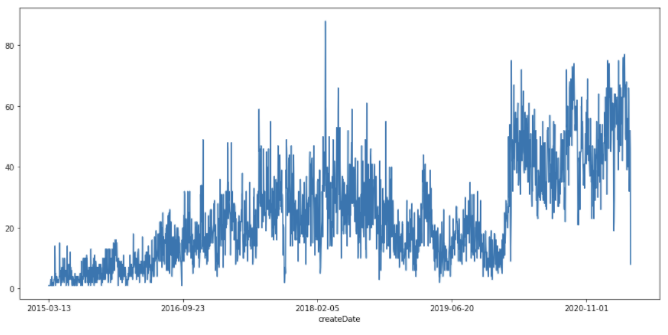
그래프를 보니 시간이 갈수록 리뷰의 개수가 늘어나는 것을 볼 수 있습니다.
'Language > Python' 카테고리의 다른 글
| 파이썬 셀레늄(selenium) webdriver자동 설치, 인스타 접속, 기다리기, 스크롤 내리기 (0) | 2019.04.27 |
|---|---|
| python selinium 크롤 할 때 랜덤 (0) | 2019.04.11 |
| 이진탐색 알고리즘 (0) | 2018.11.11 |
| python string tokenizer (0) | 2018.11.01 |
| Pyhon Tdd하기 - test코드 만들기 with pycharm (0) | 2018.09.04 |
- Total
- Today
- Yesterday
- 도커컨테이너
- 개발자
- 이직
- vim
- 도커각티슈케이스
- 도커티슈케이스
- 2017 티스토리 결산
- docker container whale
- docker container tissue box
- Linux
- 도커티슈박스
- 도커각티슈박스
- Sh
- shellscript
- docker container
- docker container tissue
- 싱가폴
- docker container case
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |