
티스토리 뷰
개요
머신러닝을 공부하다 보면 붓꽃 예제와 숫자 인식하는 예제부터 따라해보게 됩니다.
그래서 95.몇%로 붓꽃과 숫자 이미지를 인식할 수 있는 모델을 만들 수 있게 되었다고 합시다.
그런데 '내가 원하는 것은 무엇이었는가?'를 생각해보면 '뭐였지?'가 됩니다. 우리가 하고 싶은 것은 데이터를 가지고 학습을 시킨 후에 또 다른 데이터를 넣으면 예측한 결과를 알려주는 '모델'을 만드는 것입니다.
그러면 다시 '어떻게 학습 시키지?'하는 질문으로 돌아오게 됩니다.
학습을 시키려고 할 때 가장 먼저 고민이 되는 것은 '모델을 어떻게 만들어야 하는가?' 입니다. 모델을 만드는 방법은 Sequential, Functional, Estimator 등등 여러 방법이 있습니다만 목적에 맞게 사용해야 제대로 예측을 합니다.
이것 뿐만 아니고 loss function은 어떤 것을 이용할 것이고 optimizer는 어떤 것을 골라야 하는지도 위 예제만 따라한다고 해서 바로 알 수 있는 것은 아닙니다.
그래서 바닥으로 내려와서 가장 간단한 모델을 만들고 이 모델이 어떻게 예측을 해내는지를 보면서 앞으로 만들어볼 모델을 다시 한번 구상해볼 수 있는 시간을 가져보겠습니다.
x = np.array([1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5])
x_test = np.array([5, 6, 7, 8])위와같이 x는 1, 2, 3, 4, 5가 있습니다. 그리고 결과는 1, 2, 3, 4, 5 이렇게 됩니다. 그래프에 그려보면 아래와 같습니다.
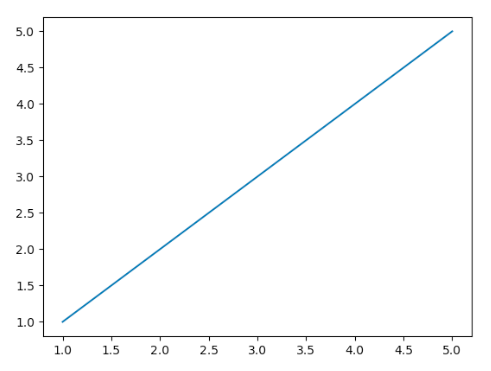
y = x형태의 일차 함수 그래프가 되겠습니다. 이런건 f = lambda x: x 로 대응이 되게 됩니다.
수학적 세계에서는 함수의 입력값과 출력값이 있겠지만 실제 세계는 그렇지 않지요.
x = np.array([1, 2, 3, 4, 5])
y = np.array([1, 2, 3.5, 4, 5])예를 들어 광고비를 태운다고 했을 때 만원을 넣었을때 매출 만원이 나왔다고 합시다. 그리고 2만원을 넣었을 때 2만원의 매출이 있었습니다.
그런데 3만원을 넣으니 3.5만원의 매출이 있었고 다시 4만원을 넣으니 4만원의 매출이 나왔습니다.
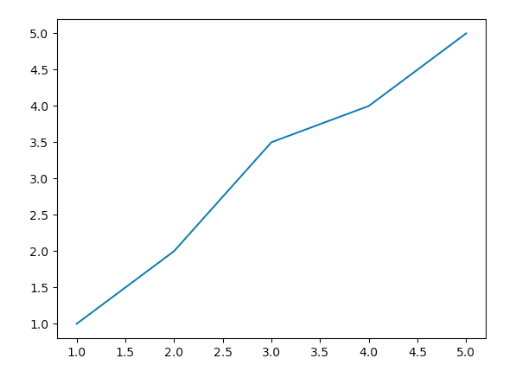
그래프에 그려보면 위와 같이 x가 3일때 y는 3.5이고 선 형태가 아닙니다.
선형인 것 같지만 어떤 규칙을 찾을 수 없을 때 패턴을 학습해서 예측을 해주는 것이 머신러닝의 목표 입니다.
그러면 이 간단한 데이터를 학습 시켜서 5, 6, 7, 8을 넣었을 때 어떤 값이 나올 것인지 예측하는 모델을 만들어 보겠습니다.
만들고 싶은 모델 정의하기
앞에서 이야기 했듯이 만들고 싶은 모델은 5, 6, 7, 8을 넣었을 때 어떤 값이 나올 것인지 예측하는 모델입니다.
데이터 준비
학습을 시킬려면 데이터가 있어야겠지요? 학습 시킬 데이터는 데이터와 정답 입니다. 학습은 여러 종류가 있습니다만 크게 보면 '지도학습'과 '비지도 학습'으로 나눌 수 있습니다. 여기에서는 '지도학습'으로 학습시킬 때 정답을 같이 학습 시킬 것입니다.
데이터는 앞에서 제시했던 데이터를 이용할 것입니다.
x = np.array([1, 2, 3, 4, 5])
y = np.array([1, 2, 3.5, 4, 5])
x_test = np.array([5, 6, 7, 8])x와 정답(Label) y를 학습 시켜 5, 6, 7, 8을 입력하면 몇이 나올 것인지를 예측 해볼 것입니다.
모델 설계하기
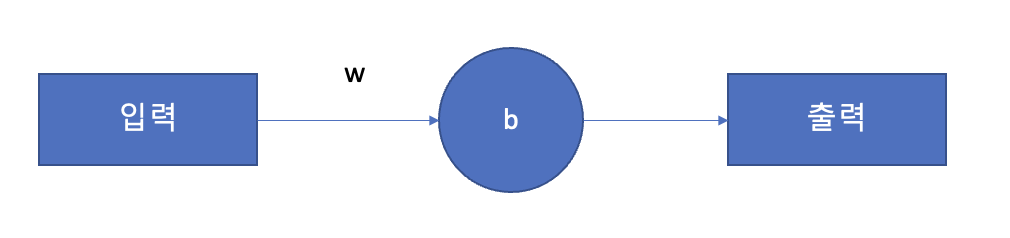
weight가 1개 있고 bias가 1개 있습니다.
모델은 아주 단순하게 만들어볼 예정입니다. 위와 같이 입력이 1개, 출력도 한개 w와 b가 각각 한개씩 입니다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(1, input_dim=1))아주 간단하지요? activation function(활성함수)는 넣지 않았습니다. keras.Dense()의 activation function default값은 None입니다. 이것의 의미는 linear입니다. linear는 선형이라는 뜻이고 1을 넣으면 1이 나오고 2를 넣으면 2가 나오는 것입니다.
다른 activation function으로는 relu, sigmoid, softmax등이 있습니다.
keras의 activation function에 대한 내용은 아래 링크를 참고 하세요
keras.io/api/layers/activations/
학습 시키기
학습 시키기 전에 먼저 컴파일을 합니다. 컴파일을 할 때 loss function과 optimizer를 넘깁니다.
model.compile(loss='mse', optimizer='sgd')loss function으로는 mse를 넣었습니다. mse는 Mean Squared Error로 평균 제곱 오차 입니다.
그리고 optimizer로는 SGD를 넣었습니다. SGD는 Stochastic Gradient Descent입니다. 확률적 경사 하강법입니다.
model.fit(x, y, epochs=40)x는 1, 2, 3, 4, 5 이고 y는 결과값인 1, 2, 3.5, 4, 5 입니다.
epochs=40은 40번을 반복 하면서 가중치 매개변수를 갱신하겠다는 뜻입니다.
예측하기
model.predict(x_test)앞에서 만든 5, 6, 7, 8값 입니다.
결과
[[5.0827436]
[6.0702767]
[7.057811 ]
[8.045344 ]]
5는 5.08로 6은 6.07로 7은 7.05로 8은 8.04로 예측 하였습니다
전체 소스코드
import tensorflow as tf
import numpy as np
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(2, input_dim=1))
model.add(tf.keras.layers.Dense(1))
model.compile(loss='mse', optimizer='sgd')
x = np.array([1, 2, 3, 4, 5])
y = np.array([1, 2, 3.5, 4, 5])
x_test = np.array([5, 6, 7, 8])
model.fit(x, y, epochs=40)
model.predict(x_test)
유투브 비디오
www.youtube.com/watch?v=7UlXVx2W0G0
참고
saengjja.tistory.com/355?category=759538
end.
- Total
- Today
- Yesterday
- 도커각티슈박스
- 도커티슈박스
- docker container tissue box
- 도커컨테이너
- docker container whale
- 도커각티슈케이스
- shellscript
- vim
- 개발자
- docker container tissue
- docker container
- 싱가폴
- docker container case
- 도커티슈케이스
- Sh
- 2017 티스토리 결산
- Linux
- 이직
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |