
티스토리 뷰
python과 aws DynamoDb 연동하기 with boto3

개요
Toy프로젝트로 '성경책 찾기' 서비스를 개발하고 있습니다. 제가 신앙심이 투철해서 그런건 아니구요 많이들 알고 있는 데이터 중에 꽤나 크면서도 다루어볼만한 것이 성경책이 적당하지 싶었습니다. 그리고 역본도 여러가지 있지만 구조는 같아서 난이도가 적당하다고 생각했습니다.
bible-finder-vue.s3-website-ap-northeast-1.amazonaws.com/
위 주소에 베타버젼이 올라가 있습니다. 현재는 호출이 올 때마다 lambda에서 9mb파일을 모두 읽은 다음 tree구조에서 스캔을 합니다.

현재는 단순 파일을 이용하지만 DynamoDB에 넣어보기로 했습니다. call당 매번 9Mb를 읽기 때문에 응답 속도가 0.5초로 그렇게 빠르지 않은 것 같다는 생각이 들었습니다. 최초 콜은 2초정도 걸리는데 아마 instance가 내려가 있어서 그런 것 같습니다.
그래서 DB에 저장을 하면 9Mb를 한번에 읽지 않아도 될 것 같다는 생각으로 Aws에 소규모로 올렸을 때 비용이 거의 안나오는 DynamoDB를 이용해 보기로 했습니다.
DynamoDB를 이용하려다보니 DynamoDB가 제가 주로 쓰던 RDB인 MySql과 다른점들이 많아서 함께 정리를 해봅니다.
Prerequisite
서비스는 Python으로 개발할 것이기 때문에 boto3라이브러리를 사용합니다.
Boto3 설치
pip install --index-url https://pypi.org/simple boto3 --trusted-host pypi.org --trusted-host files.pythonhosted.org
DynamoDB 로컬실행
AWS의 DynamoDB를 이용하더라도 개발과 테스트는 로컬에서 하는게 맘 편하기 때문에 로컬에 DynamoDB 인스턴스를 띄우고 작업 했습니다.
AWS DynamoDB 로컬 실행
개요 AWS Lambda를 이용하면 월 100만건까지 무료로 웹에 api를 구축할 수 있습니다. 하지만 람다는 저장소가 없습니다. 비용을 무료로 쓰려고 Lambda를 쓰는데 Rds를 띄워서 매달 얼마씩 낸다고 하면
krksap.tistory.com
Dynamodb를 쓰는 이유
25GB까지는 무료로 사용 가능하기 때문입니다. 하지만 25GB까지 무료라는 것이 거의 유일한 장점이라고 할 수 있습니다.
Write, Read는 저장용량 25GB와는 별개의 비용이 발생 합니다.
Dynamodb비용
비용은 쓰기가 읽기보다 비쌉니다. 쓰기는 단위를 1kb당으로 받고 읽기는 4kb당으로 가격을 받습니다.
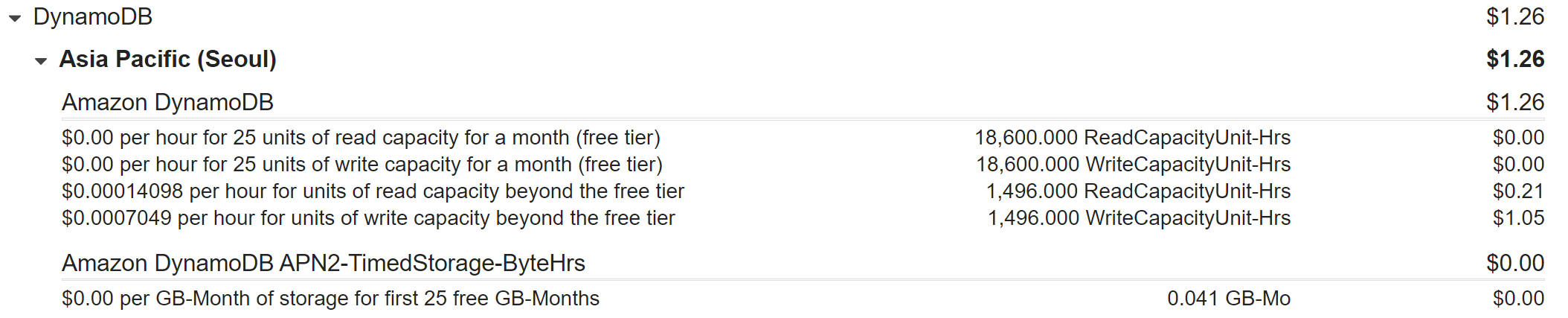
제가 한달동안 사용한 비용은 위와 같이 1.26입니다. 제가 이용한 것은1496읽기 단위를 이용 했는데요 비용이 1.26불이 나왔습니다.
| 비용 | 사용량 | MB | 계 |
| 0.00014098 | 1496 | 5.8 | 0.21090608 |
| 0.0007049 | 1496 | 1.4 | 1.0545304 |
읽기 1496이면 4kb * 1496을 썼다는 의미 입니다. 읽기는 약 5.8MB 쓰기는 1.4MB를 사용한 것입니다. 5.8MB에 0.21불이 나온 것입니다. 30MB정도 읽기로 썼으면 1불 정도 나왔을 것 같습니다.
쓰기 1496이면 1496kb를 썼다는 것이고 1.5메가 정도 됩니다. 1.5MB에 1불이 넘기 때문에 1MB쓰는데 약 1불이 든다고 보시면 됩니다. 그러면 70MB씩 매일 Write를 한다면 하루에 70불 정도 비용이 발생합니다.
프리티어는 시간당 25 단위의 용량에 대해 매달 18,600씩 준다는 것입니다.

저는 1개의 테이블만 이용 했고 이 테이블의 프로비저닝 읽기 쓰기 단위는 10으로 초당 10킬로바이트만 쓸 수 있습니다.
예를들어 1개의 row가 1kb인 데이터 1000개라면 1000kb로 1mb입니다. 그래서 1초에 10개의 요청을 보낼 수 있고 1메가를 쓰는데 100초가 걸리는 것입니다.
1메가 쓰는데 1분 걸린다고 치면 제가 하루에 db에 쓰는 데이터가 70메가 인데 70메가 쓰는데 거의 2시간이 걸린다는 것입니다.
Dynamodb제약 사항
Dynamodb는 NoSql이기 때문에 우리가 익숙한 RDB의 쿼리는 대체로 안된다고 생각하시면 됩니다.
그리고 한 row에 저장할 수 있는 데이터가 400kb뿐이고 한번에 조회할 수 있는 데이터 양도 1MB뿐입니다. 결과가 1MB 이상이라면 Paging을 해야 합니다.
이런 제약사항이 있기 때문에 속도가 빠른 것입니다.
Partition Key와 Sort Key
다이나모 DB에 들어가는 row는 Primary Key가 필요 합니다. Primary Key가 될 수 있는 것은 파티션키 또는 파티션키와 소트키의 조합입니다. 그래서 Partition Key와 Sort Key를 조합했을 때의 값이 유니크 해야합니다.
| 반 | 번호 |
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
| 2 | 2 |
| 2 | 3 |
위와 같이 학교에 반과 번호가 있다고 했을 때 반은 1반과 2반이 있고 각 반에 1번부터 n번까지가 있는 경우는 반 + 번호의 조합이 유니크 하기 때문에 가능합니다.
하지만 여기에 '학년'이 들어간다면 문제가 있겠지요?
| 학년 | 반 | 번호 |
| 1 | 1 | 1 |
| 1 | 2 | 1 |
| 1 | 2 | 2 |
| 2 | 1 | 1 |
| 2 | 2 | 1 |
| 2 | 2 | 2 |
위와 같이 학년 + 반 + 번호까지 조합을 해야 유니크가 되는 경우는 Dynamo DB에 맞지 않습니다.
하지만 아래와 같은 경우는 DynamoDB가 유리합니다.

Sort Key가 timestamp이고 Type이 Number입니다. 이 경우 Sortkey에 between연산을 할 수 있습니다. 그래서 날짜 형식이나 날짜+시간 형식의 데이터가 있다면 timestamp로 변환 해서 넣으면 좋을 것입니다.
GSI, LSI
GSI는 Global Secondary Index의 약자이고 LSI는 Local Secondary Index의 약자 입니다.
Global Secondary Index는 PK와 SK와 상관 없이 Table전체에서 검색 합니다.
Local Secondary Index는 PK안에서 작동하는 인덱스 입니다.
웬만하면 Local Secondary Index를 이용하는게 DB연산을 줄일 수 있겠지요?
Table만들기
.create_table()을 이용합니다.
Partition Key는 'chapter'으로 했고 Sort key는 'verse'로 Table을 만들었습니다. 이렇게 생성하면 key가 2개가 되는 것입니다. 성경책은 창세기 1장 1절 이렇게 총 3가지를 가지고 구절을 찾습니다. 그래서 창세기 1장을 창1로 통합하여 key를 구성 했습니다.
KeySchema=[
{
'AttributeName': 'chapter',
'KeyType': 'HASH' # Partition key
},
{
'AttributeName': 'verse',
'KeyType': 'RANGE' # Sort key
}
],
AttributeDefinitions=[
{
'AttributeName': 'chapter',
'AttributeType': 'S'
},
{
'AttributeName': 'verse',
'AttributeType': 'N'
}
],Key는 2개 이상 들어갈 수 없습니다.
KeySchema=[
{'AttributeName': 'shortened_book_nm', 'KeyType': 'HASH'}, # Partition key
{'AttributeName': 'chapter', 'KeyType': 'RANGE' }, # Sort key
{'AttributeName': 'verse', 'KeyType': 'RANGE' } # Sort key
],위와 같이 키 3개로 해도 생성이 되지 않습니다.
다음 코드는 테이블을 생성하는 코드 입니다.
import boto3
def create_book_table(dynamodb=None):
if not dynamodb:
dynamodb = boto3.resource('dynamodb', endpoint_url="http://localhost:8000")
table = dynamodb.create_table(
TableName='Book',
KeySchema=[
{
'AttributeName': 'chapter',
'KeyType': 'HASH' # Partition key
},
{
'AttributeName': 'verse',
'KeyType': 'RANGE' # Sort key
}
],
AttributeDefinitions=[
{
'AttributeName': 'chapter',
'AttributeType': 'S'
},
{
'AttributeName': 'verse',
'AttributeType': 'N'
}
],
ProvisionedThroughput={
'ReadCapacityUnits': 10,
'WriteCapacityUnits': 10
}
)
return table
또 다른 예제 With LocalSecondaryIndex
def create_table(self, table_name):
table = self.dynamodb.create_table(
TableName=table_name,
KeySchema=[
{
'AttributeName': 'stdSpciesNewCode',
'KeyType': 'HASH'
},
{
'AttributeName': 'delngDe',
'KeyType': 'RANGE' # Sort key
}
],
AttributeDefinitions=[
{
'AttributeName': 'stdSpciesNewCode',
'AttributeType': 'S'
},
{
'AttributeName': 'delngDe',
'AttributeType': 'N'
},
{
'AttributeName': 'price',
'AttributeType': 'N'
}
],
LocalSecondaryIndexes=[
{
'IndexName': 'code_price',
'KeySchema': [
{
'AttributeName': 'stdSpciesNewCode',
'KeyType': 'HASH'
},
{
'AttributeName': 'price',
'KeyType': 'RANGE'
},
],
'Projection': {
'ProjectionType': 'ALL'
},
}
],
ProvisionedThroughput={
'ReadCapacityUnits': 10,
'WriteCapacityUnits': 10
}
)
테이블 리스트 보기
dynamodb에 있는 모든 table을 가지고 오는 코드 입니다.
위 print_table과 다른 점은 boto3.resource()대신 boto3.client()를 쓴다는 것입니다.
import boto3
dynamodb = boto3.client('dynamodb')
tables = dynamodb.list_tables()
print(tables)결과
{'TableNames': ['auction2'], 'ResponseMetadata': {...생략...}}
함수 형태
def list_table():
dynamodb = boto3.client('dynamodb', endpoint_url="http://localhost:8000")
response = dynamodb.list_tables()
return response
print(list_table())
DB에 데이터 넣기 - Insert
DynamoDB는 key auto increment를 지원하지 않기 때문에 key를 unique하게 만들어주는게 간단하게 insert할 수 있는 방법입니다. 그래서 uuid()를 써서 id를 만들어주고 insert를 했습니다.
def insert_a_row(table_name, row):
dynamodb = boto3.resource('dynamodb', endpoint_url='http://localhost:8000')
table = dynamodb.Table(table_name)
r = table.put_item(Item=row)
print(r)
b = {
'chapter':'김1',
'verse':2,
'text':'bye'
}
insert_a_row('Book', b)
row안에 또 다른 row insert하기
rdb는 row안에 row를 넣을 수 없지만 nosql은 이게 가능 합니다. 넣을 수 있는 것 뿐만 아니라 여기에 filter도 가능합니다.
def insert_a_row(row):
dynamodb = boto3.resource('dynamodb', endpoint_url='http://localhost:8000')
table = dynamodb.Table('table01')
r = table.put_item(Item=row)
print(r)
row = {
'date':'20210509',
'wcode':1,
'items':[
{'id':'1', 'name':'krk'},
{'id': '2', 'name': 'kr2'}
]
}
insert_a_row(row)결과
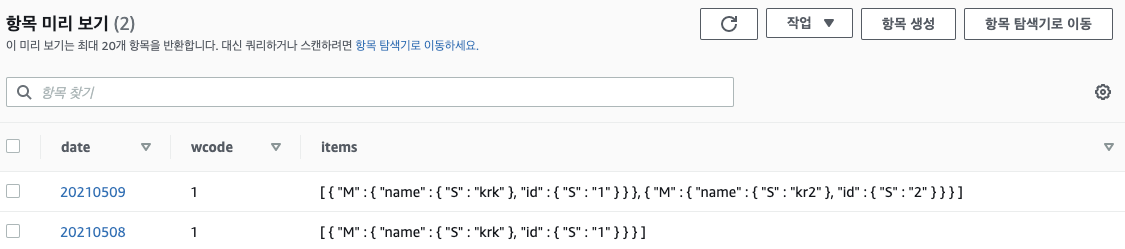
위 결과에서 [{"M":{}}, {"M":{}}] 이런식으로 데이터가 들어가 있습니다 M은 Map입니다. S는 String이고 N은 Number입니다.
참고 DynamoDb Attribute Type
docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_AttributeValue.html
데이터 뽑기 - Select
.get_item()을 쓰면 1개의 데이터를 꺼내옵니다. 같은 key로 데이터가 2개 이상 들어있다면 마지막에 넣은 데이터가 나옵니다.
def read_rows(table_name, row, q):
dynamodb = boto3.resource('dynamodb', endpoint_url='http://localhost:8000')
table = dynamodb.Table(table_name)
try:
r = table.get_item(Key=q)
except ClientError as e:
print(e.response['Error']['Message'])
return r['Item']
read_rows('Book', b, {'shortened_book_nm':'김', 'chapter':1})
select all
def select_all(table_name):
table = self.dynamodb.Table(table_name)
r = table.scan()
return r결과
{'Items': [], 'Count': 0, 'ScannedCount': 0, 'ResponseMetadata': {'RequestId': 'BJS3SN18C6HCVNBSOK640CIIQRVV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Tue, 11 May 2021 08:12:05 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '39', 'connection': 'keep-alive', 'x-amzn-requestid': 'BJS3SN18C6HCVNBSOK640CIIQRVV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '3413411624'}, 'RetryAttempts': 0}}
Query Range Between
response = table.query(
KeyConditionExpression=
Key('year').eq(2020) & Key('title').between('A', 'L')
)year가 2020이고 title이 A로 시작하는 것부터 L로 시작하는것까지 호출 합니다. Partition key는 between이 안되고 eq만 지원 합니다. between, begins with등의 기능을 이용하려면 Sort key에 걸어야 합니다.
Sort key Begins with
sort key를 복합키(composition key)로 지정 한 경우 앞에 한가지 조건만으로도 쿼리가 가능 합니다.
여기에서 prdcd_whsal_mrkt_new_cd는 prdcd와 whsal_mrkt_new_cd를 #으로 연결하여 지정 하였습니다.

db를 위와 같이 설계한 경우 .begins_with()를 이용해 prdcd만 가지고도 쿼리를 할 수 있습니다.
def select_pk_begins_with(self, date):
response = self.table.query(
KeyConditionExpression = Key('date').eq(date)
& Key('prdcd_whsal_mrkt_new_cd').begins_with('1202#')
)
print(response)
Limit
def select_by_pk(pk):
response = self.table.query(
KeyConditionExpression=Key('date').eq(pk),
Limit=100
)
return response
Paging
offset같이 from to 의 쿼리는 dynamo에서는 지원하지 않습니다.

aws의 '항목탐색기'도 처음 로딩 했을 때는 1페이지만 보며주고 next버튼을 눌러야 2페이지가 나옵니다. 총 몇페이지인지는 모두 조회 해보기 전까지는 알 수 없습니다. 이것이 dynamodb의 특성입니다.
ExclusiveStartKey에 lastEvaluatedKey넣기
def select_by_pk(self, pk, last_evaluated_key=None):
if last_evaluated_key == None:
response = self.table.query(
KeyConditionExpression=Key('date').eq(pk),
Limit=100
)
else:
response = self.table.query(
KeyConditionExpression=Key('date').eq(pk),
ExclusiveStartKey = {'date':pk, 'prdcd_whsal_mrkt_new_cd':last_evaluated_key},
Limit=100
)그래서 LastEvaluatedKey를 넣어야 합니다. LastEvaluatedKey는 query를 하고 나면 결과에 들어있습니다.
필터링 하기
def select_statistic(self, pk):
response = self.table.query(
KeyConditionExpression = Key('date').eq(pk) & Key('prdcd_whsal_mrkt_new_cd').begins_with('CRAWL#'),
FilterExpression = 'total_cnt > :v',
ExpressionAttributeValues= {
':v': 0,
},
Limit=100
)
return response위 쿼리는 pk가 date인 Table에서 파라메터로 받은 pk와 일치하는 데이터 그리고 sk(sort key)인 prdcd_shsal_mrkt_new_cd가 'CRAWL#'으로 시작되는 데이터 중 total_cnt가 0보다 큰 데이터를 100개만 가지고 오는 쿼리 입니다.
로컬 테스트 결과
로컬에서 성경책 한권(9Mb)을 DynamoDB에 넣어봤더니 571초가 걸렸습니다. 거의 10분정도 걸렸습니다. 에러는 한번도 안났습니다. 총 구절 수는 31107개여서 row도 31107개가 생성 되었습니다.
[Done] exited with code=0 in 571.06 second
로컬 -> 도쿄리전 테스트 결과
Single Thread
싱글스레드는 http request, response 속도의 영향을 넘나 많이 받기 때문에 느립니다. 1초에 3개 들어갑니다. 3만개 넣을려면 하루종일 걸립니다.


항목 수와 업데이트 날짜로 확인 해보면 30초 동안 100개 정도 들어갔습니다. 3만개 쓸려면 9000초 정도 걸리겠네요. 3시간 정도 예상 됩니다.
Multi Thread
PC마다 차이가 있겠지만 Thread로 하면 초당 처리할 수 있는 개수가 훨씬 많이 늘어납니다.
def insert_a_book_into_db(self, fr=0, to=0):
cnt = 0
with open('tree_gae.json') as f:
jo = json.load(f)
keys = list(jo.keys())
print(type(keys), keys)
for key in keys[fr:to]:
for chapter in jo[key]:
for verse in jo[key][chapter]:
print(cnt,len(jo[key]), len(jo[key][chapter]), jo[key][chapter][verse], flush=True)
b = {
'chapter':f'{key}{chapter}',
'verse':int(verse),
'text':jo[key][chapter][verse]
}
Thread(target=lambda x: self.insert_a_row('Book', x), args=([b])).start()
# self.insert_a_row('Book', b)
# print(jo[key][chapter][verse])
cnt += 1
print(cnt)위 코드는 멀티스레드로 튜닝한 코드 입니다.


1초에 3개 들어갔네요.
로컬 처리 속도와는 무관하게 서버 처리속도가 영향을 주는 것 같습니다.
end.
Refer
docs.aws.amazon.com/amazondynamodb/latest/developerguide/GettingStarted.Python.01.html
'Language > Python' 카테고리의 다른 글
| python uuid만들기 (0) | 2018.07.11 |
|---|---|
| python yyyy-mm-ddThh:mm:ss (0) | 2018.05.02 |
| python [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed 이 이러 나는 경우 해결 방법 (5) | 2018.04.26 |
| python으로 Excel(엑셀) 데이터 다루기 (0) | 2018.04.12 |
| json 형식 (0) | 2018.02.17 |
- Total
- Today
- Yesterday
- shellscript
- 도커컨테이너
- 2017 티스토리 결산
- 개발자
- 싱가폴
- 도커티슈박스
- docker container tissue box
- 도커각티슈박스
- 도커티슈케이스
- docker container
- Sh
- Linux
- docker container whale
- vim
- 이직
- docker container tissue
- docker container case
- 도커각티슈케이스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |