

티스토리 뷰
AWS 글루란?
ETL서비스로 AWS에 있는 RDS, Dynamodb, S3, Redshift 등에 있는 데이터를 불러와주는 기능을 하는 어플리케이션 입니다.
ETL이란
Extract
Transform
Load
의 약자입니다.

위 그림에 나와 있듯이 Source에서 데이터를 가지고 와서 매핑, 조인, 필터링, 커스터마이징을 하고 S3나 Glue Catalog인 Redshift, RDS 등에 저장하는 작업 입니다.
언제 사용하나요?
1. 기존에 구축해놓은 데이터 웨어하우스에서 AWS로 데이터를 불러올때, AWS에서 데이터 웨어하우스로 데이터 전송 할 때
2. ETL 파이프라인 구축 할 때
왜 사용하나요?
데이터가 RDS, Dynamodb, S3, Redshift 이런 곳에 나누어져 있는 경우 각 어플리케이션을 인터페이스 해서 데이터를 불러오기란 쉽지 않습니다.
예를들면 User데이터는 RDS에 들어있고 사용자가 활동한 로그 정보는 DynamoDB에 있고 API로부터 수집한 데이터는 S3에 있다고 했을 때 이 데이터들을 모두 불러와 학습을 시키려면 너무나 어렵습니다.
www.youtube.com/watch?v=LkkgtNtuEoU
S3 Bucket만들기
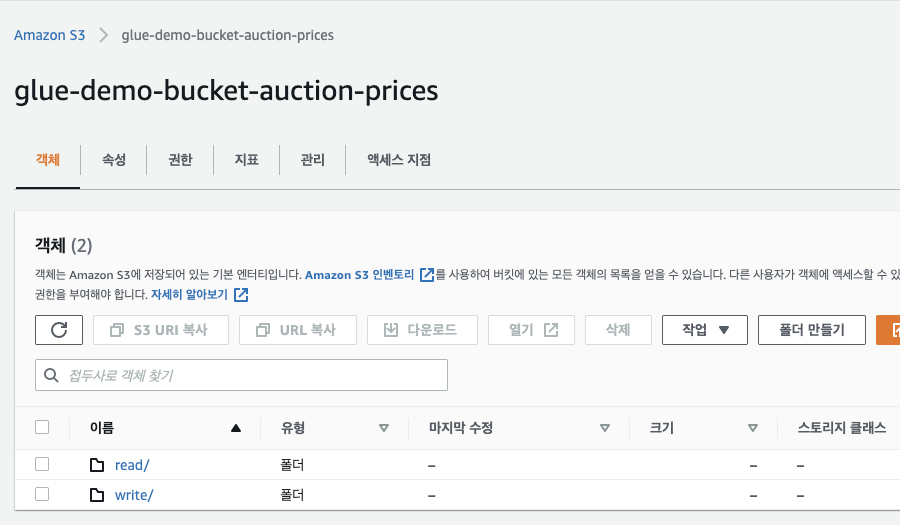
read에는 로컬에서 데이터가 들어있는 파일을 올릴 것입니다.
크롤러 만들기
크롤러는 데이터 스토어에 연결하고 데이터 카탈로그에 메타데이터 테이블을 생성합니다. 메타데이터 테이블이란 테이블 스키마라고 생각하시면 됩니다. row가 insert되지는 않고 create table만 된다고 생각하시면 됩니다.
여기에서 데이터 스토어는 S3입니다.



CreateDatabase
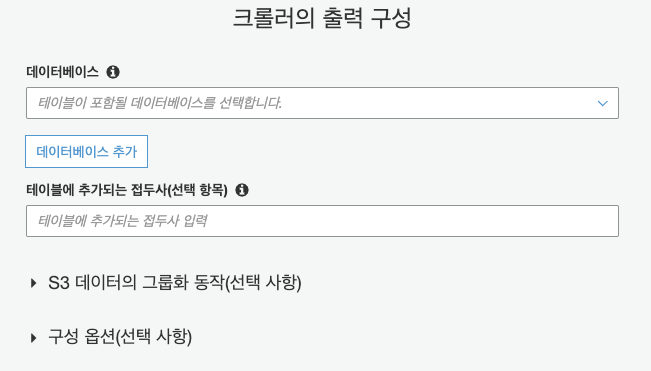
데이터베이스 추가를 누릅니다.

데이터베이스 이름만 입력하고도 만들 수 있습니다.
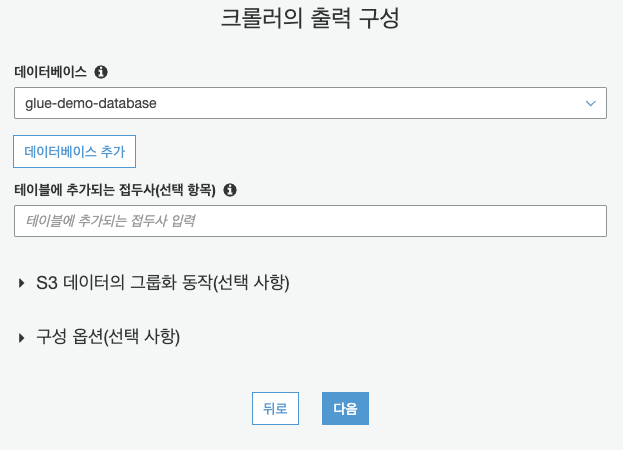
다음을 누릅니다.
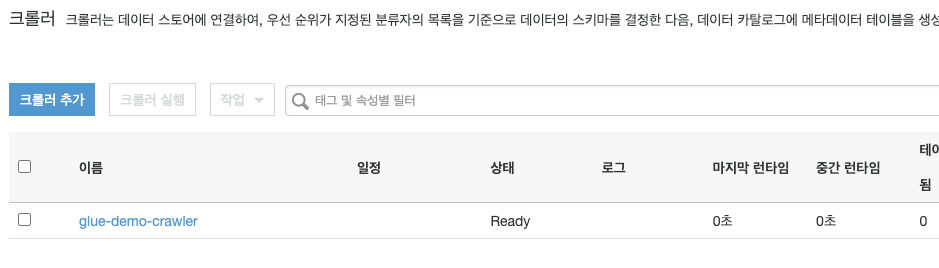
크롤러가 만들어졌습니다.
데이터베이스를 확인 해봅니다.

크롤러를 아직 실행 하지 않았기 때문에 데이터베이스에 아무런 테이블이 없습니다.
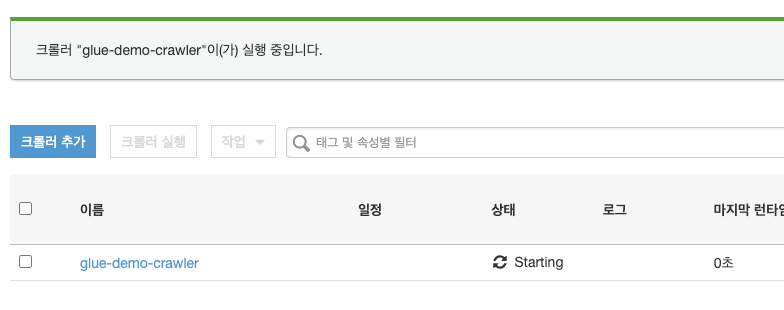
크롤러 실행을 합니다. 그러면 상태가 'Starting'으로 바뀝니다.
Table이 안만들어지는 이유
.json에서만 테스트 해보았지만 데이터가 아래와 같이 {'data':[{}, {}, {}]} 이런식으로 되어 있으면 테이블이 생성이 안되었습니다.


cloud watch로그를 봐도 성공한 경우와 실패한 경우가 차이를 발견하지 못했습니다. 11시 58분에 실행한 것은 실패하여 테이블이 안생겼지만
14시 14분에 실행한 것은 테이블이 생성이 되었습니다. 하지만 로그는 똑같이 남아있어서 왜 그런지 이유를 추측해서 검증해야 했습니다.

성공한 경우는 '테이블 추가됨'에 1이라고 나옵니다.

성공한 경우는 위와 같이 [{}, {}, {}] 리스트 안에 바로 {}가 들어있으면 테이블이 생성이 됩니다.

그런데 {'key':'value'} 이런 형태로 데이터가 들어있어서 그런지 데이터 형식이 array로 잡혔습니다.

눌러보면 위와 같이 필드명에 type이 매핑된 화면이 나옵니다.
내장 JSON 클래시파이어를 이용하는 경우에 JSON파일을 그냥 불러오면 array로 나옵니다. 이 경우는 전형적인 경우로 AWS도큐먼트의 맨 앞에 나오는 내용입니다.
도큐먼트에는 JSON Paht라고 나옵니다만 파일의 위치가 아니라 JSON Path는 object안에서의 위치를 말합니다.

그래서 분류자를 $[*]를 사용합니다.

분류자를 생성 했으면 크롤러에도 어사인(assign) 해줍니다. 어사인 안하고 돌리면 또 array로 나옵니다.

Classifier를 잘 설정 하고 돌리시면 아래와 같이 스키마가 잘 생성된 것을 볼 수 있습니다.

혹시나 데이터가 들어있는지 확인하는 방법이 있습니다.
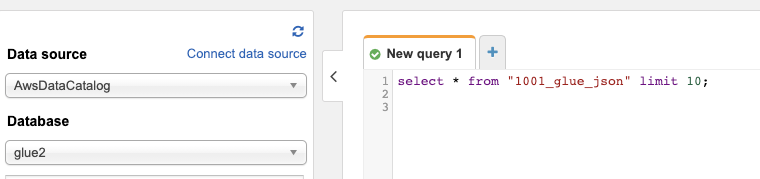
AWS 아테나(Athena)로 가셔서 select query를 날려보시면 데이터가 없다고 나옵니다.

아래 링크는 커스텀 분류자 문서입니다.
custom classifier link
https://docs.aws.amazon.com/glue/latest/dg/custom-classifier.html#custom-classifier-json
Writing Custom Classifiers - AWS Glue
Writing Custom Classifiers You can provide a custom classifier to classify your data in AWS Glue. You can create a custom classifier using a grok pattern, an XML tag, JavaScript Object Notation (JSON), or comma-separated values (CSV). An AWS Glue crawler c
docs.aws.amazon.com
AWS Glue Job 생성하기(Authoring Jobs)
https://docs.aws.amazon.com/glue/latest/dg/author-job.html
Authoring Jobs in AWS Glue - AWS Glue
Authoring Jobs in AWS Glue A job is the business logic that performs the extract, transform, and load (ETL) work in AWS Glue. When you start a job, AWS Glue runs a script that extracts data from sources, transforms the data, and loads it into targets. You
docs.aws.amazon.com
Job은 Aws Glue에서 ETL을 수행하는 비즈니스 로직입니다. 데이터를 뽑고(Extract), 전송하고(Transfer), 불러오고(Load)하는 로직이 되겠습니다. Job을 실행하면 Glue는 데이터를 추출하는 스크립트를 실행하고 됩니다.
Glue Studio -> Jobs로 갑니다.
아래 화면에서 Create를 누릅니다.

어디에서 데이터를 뽑아올 것인지를 설정 합니다.
S3 bucket을 누릅니다. 오른쪽에 Data source properties - S3 에서 Database, Table을 선택 합니다.

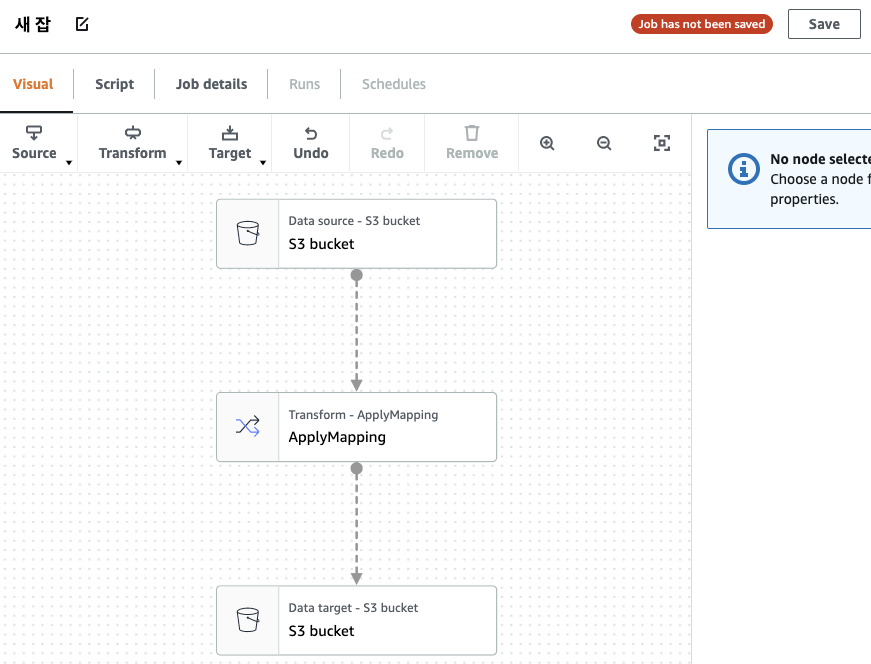
데이터가 어디로 갈 것인지도 정해줍니다.

Job details로 갑니다.

여기에서 IAM Role을 잘 설정 해주어야 합니다.
저는 PowerUser로 했습니다.

우리가 만든 Job이 s3에서 Data를 read해야 하고 write도 해야 합니다. 그래서 롤을 찾아서 바인딩 하는 대신에 파워유저로 퉁쳤습니다.
job은 여러개의 Node로 구성 되어 있습니다.


이런 하나하나가 노드 입니다.
위 과정을 거치면 아래와 같은 스크립트가 만들어집니다.

ETL작업은 패턴이 비교적 뻔하기 때문에 gui에서도 각 Node를 연결해 flow를 만들 수 있습니다. 또한 이 스크립트를 편집 할 수도 있습니다.
Python boto3 code
import boto3
client = boto3.client('glue')
def get_tables():
res = client.get_classifiers()
print(res)
def get_crawlers():
return client.get_crawlers()
if __name__ == '__main__':
# print(get_crawlers()['Crawlers'])
# print(client.get_crawler(Name='crawler2'))
# print(client.get_tables(DatabaseName='glue2'))
table_list = client.get_tables(DatabaseName='glue2')['TableList']
for i in table_list:
print(i)
table_name = 'read_json_example'
res = client.get_table(DatabaseName='glue2', Name=table_name)
for f in res['Table']:
print(f)
print(res['Table'].get('Parameters'))
job = client.get_job(JobName='새 잡')['Job']
for k, v in job.items():
print(k, v)
- Total
- Today
- Yesterday
- docker container tissue box
- 이직
- Linux
- 개발자
- 도커각티슈박스
- shellscript
- 도커티슈박스
- 도커티슈케이스
- vim
- docker container tissue
- Sh
- 도커각티슈케이스
- 도커컨테이너
- docker container
- 싱가폴
- 2017 티스토리 결산
- docker container whale
- docker container case
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |